Logsysteme sind für einen sicheren IT-Betrieb unerlässlich. Wer eine Zertifizierung nach BSI Grundschutz-Kompendium oder auch ISO 27001 aufrecht erhalten muss oder ganz simpel wissen möchte, was das IT-System macht, der kommt an einem System für Logging nicht vorbei.
Eine Systemauswahl ist ein Prozess, bei dem wir zu Beginn Kriterien, Anforderungen und ein Bewertungsschema festlegen. Anschließend nehmen wir alle in Frage kommende Systeme und prüfen sie dagegen. Eine erste Stufe der Prüfung könnte beispielsweise eine reine Prüfung öffentlicher Informationen (Webseite, Erfahrungsberichte) sein. Am Ende der Prüfung können dann fünf konkrete Kandidaten in einen Proof-Of-Concept (PoC) geschoben werden.
Disclaimer: das Ergebnis einer Systemauswahl ist entscheidend davon abhängig, welche Kriterien und Anforderungen wir erhoben haben. Der folgende Text sagt nicht, dass die Software schlecht oder gut ist, sondern dass sie entsprechend der Anforderungen geeignet ist. Einem MS365-only Unternehmen brauchen wir keine Linux-Docker-Lösung auf ProxMox vorschlagen.
Begriffe und ein gemeinsames Verständnis
Bei unseren Recherchen und Kundengesprächen kamen zwei streitbare Aspekte zum Vorschein: Protokollierung vs. Logging sowie Logging vs. Monitoring.
Ganz nüchtern betrachtet verstehen wir unter dem Begriff Protokollierung die Nachhaltung und Aufzeichnung von Systemveränderungen, also einfach runtergebrochen: Wer hat wann was gemacht! Das Logging erweitert aber die Protokollierung um Statusveränderungen auf IT-Systemen, die dann auch für Fehlersuche oder dem Monitoring unterstützen können. Die Protokollierung nutzt das Thema Logging und baut das Ganze in die Prozesslandschaft (Compliance, Nachweisbarkeit, Nachverfolgbarkeit). Der BSI IT-Grundschutz benutzt den Begriff Protokollierung, da es auf die Nachweisbarkeit und Nachverfolgbarkeit des Informationsverbundes fokussiert ist. Der IT-Betrieb muss jedoch die Wartung und Pflege der IT-Systeme sicherstellen und möchte daher das Logging nutzen.
Die Unterscheidung von Logging und Monitoring ist dagegen eine sehr technische: das Logging bekommt passiv sehr viele Informationen von den Systemen, und führt die Auswertung durch. Das Monitoring-System dagegen fragt aktiv an, wie der Zustand von vorab definierten Metriken ist. Fällt ein System aus, bekommt ein Monitoring-System das durch die aktive Abfrage schnell mit. Das Logsystem könnte ggf. nur feststellen, dass keine Daten von einem System mehr reinkommen.
Longlist der Logging-Kandidaten
Hier sind nun einige Kandidaten, die für das Thema Logging in Frage gekommen sind.
- Splunk
- Elastic Search
- Graylog
- Open Search
- Grafana Loki
- Logstash
- Fluentd
- Flume
- rsyslog
- syslog-ng
- PRTG
- Nagios
- CheckMK
Tatsächlich sind das mit die häufigsten Ergebnisse, wenn man nach dem Thema „Logging System“ sucht. Allerdings sind diese Anwendungen oft sehr unterschiedlich, so dass man sie überhaupt nicht vergleichen kann und diese Anwendungen eher unterschiedlichen Spezialaufgaben innerhalb eines Logging-Systems durchführen.
Das Elastic-Ökosystem erklärt
Am schwierigsten war es für uns, das Elasticsearch-Universum zu durchdringen. Logstash ist ein Empfänger von Logs, kann diese transformieren und an ein anderes System weitergeben. In der Regel findet eine Ingestion in Elasticsearch statt. ES ist eine Suchmaschine und kann die ihm übergebenen Dokumente (z.B. eine Syslog-Nachricht) durchsuchen. Elasticsearch hat jedoch keine GUI, sondern nur eine API-Schnittstelle, die die Suchanfragen empfängt und darüber auch die Ergebnisse zurück liefert. Für die GUI ist bei Elastic Search wiederum Kibana zuständig. Hier kann man die Suchabfragen durchführen, sortieren, grafisch aufbereiten und für später speichern.
Also in kurz: Logstash empfängt und pumpt nach Elasticsearch. Elastic übernimmt Suchaufträge und gibt die Ergebnisse zurück. Kibana ermöglicht das über den Browser und macht das ganze hübsch. Darum nennt man das ganze auch ELK-Stack, auf Grund der Anfangsbuchstaben seiner Komponenten.
Ist doch einfach, oder? 🙂
Negativ ist, dass logstash eine eigene Software ist, die nicht über Kibana administriert werden kann. Hier gilt es knallhart auf die Konfigurationsdatei-Ebene hinunter zu gehen (inklusive einem Stillstand der Logverarbeitung, wenn man eine geschweifte Klammer vergessen hat).
Es ist nach meinem Wissensstand auch nicht möglich, die Konfigurationsdatei zu modularisieren. Sprich, für Logstash empfehlen wir dringend in Produktivumgebungen eine gute QS-Umgebung.
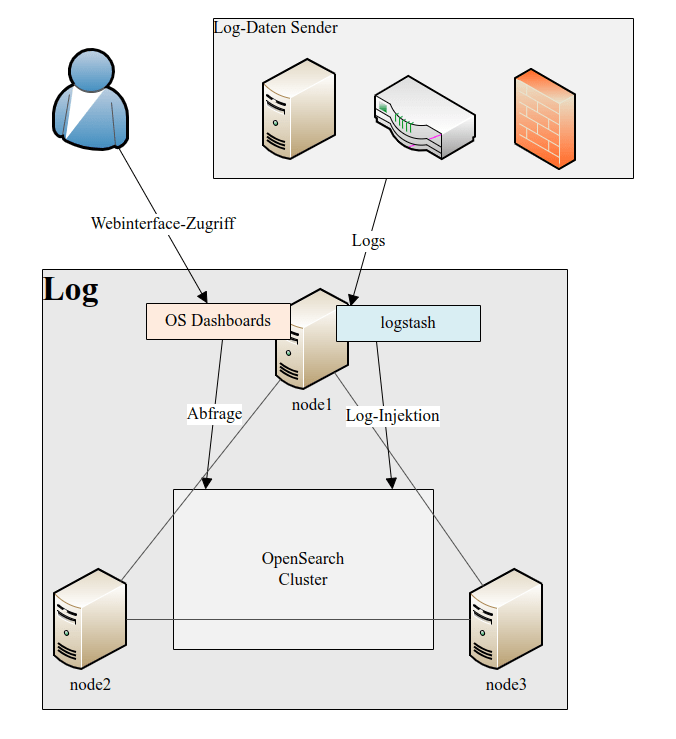
Eine Elasticsearch lässt sich komplett auf einem Server installieren: Logstash, ES und Kibana schlummern dann unter einem Betriebssystem. Es lässt sich allerdings auch verteilen, clustern und skalieren, das heißt, wir können 5 Server bereitstellen und ES verteilt die Dokumente auf diese Knoten. Bei der Suche werden diese Dokumente durch die Verteilung auf die Knoten auch schneller gefunden als auf einem großen Server. Verantwortlich für die Qualität der Suchanfragen ist Apache Lucene, das unter der Haube von Elasticsearch werkelt.
Muss man logstash mit Elasticsearch nehmen? Nein, es gibt theoretisch auch andere Log Shipper. Dazu gehören Filebeat, Fluentd und Fluent Bit. In der Praxis trifft man dagegen häufig logstash an.
Muss man Kibana für Elasticsearch nehmen? Nein, es gibt theoretisch andere GUIs. Beispielsweise hat Grafana die Möglichkeit, auf Elasticsearch zuzugreifen. In der Praxis trifft man aber auch hier häufig auf Kibana.
Was ist nun OpenSearch?
Die Firma hinter Elasticsearch war im Streit mit Amazon und wollte AWS die Nutzung von ES im AWS-Kontext bezahlen lassen. Also hat AWS Elasticsearch geklont, beziehungsweise abgespalten, es lizenztechnisch freigemacht (Apache 2.0) und unter einem neuen Namen an die Community zurückgegeben. Für Lizenz-sensible Organisationen ist OpenSearch eher als Elasticsearch zu empfehlen.
- Logempfänger: Logstash / Logstash
- Suchmaschine: Elasticsearch / OpenSearch
- GUI: Kibana / OpenSearch Dashboards
Die Administration und Konfiguration vom Logempfänger und der Suchmaschine ist ziemlich identisch. Die meisten Aussagen zu Elasticsearch gelten auch für Opensearch (Verteilung, Clusterung, Architektur, etc.).
OpenSearch versucht kompatibel zum anderen Projekt zu bleiben. So erlaubt OpenSearch den Zugriff von Kibana auf seine Software, Elastic aber widerum verbietet OpenSearch Dashboards den Zugriff auf Elasticsearch.
Bei der GUI muss OpenSearch Dashboards noch einiges aufholen, da offensichtlich noch mehr Menschen auf Kibana setzen. Leider ist die Logstash-Administration ist hier nicht anders.
Graylog
Graylog hatte sich frühzeitig Elastic Search als Suchmaschine geschnappt, einen eigenen Logempfänger gebaut und den sehr schön in das eigene Webinterface integriert. Das Onboarding von neuen Quellen nebst Sockets und Extraktoren ist alles über das Webinterface möglich.
Inzwischen hat Graylog auch von Elastic Search auf OpenSearch gewechselt. Für den Nutzer ändert sich dabei gar nichts.
Allerdings ist die Firma hinter Graylog dabei, die Nutzer mehr und mehr davon zu überzeugen, Geld für Zusatzfunktionen auszugeben. Funktionen, die insbesondere in der Arbeit mit mehreren Personen benötigt werden, kosten Geld. So ist beispielsweise auch die Weiterleitung von Logdaten, zum Beispiel an das SIEM in der Konzernzentrale, nicht mehr ohne Zusatzlizenzen möglich.
Die Software-Architektur ist bei Graylog eher monolithischer als bei ELK oder OSD. Eine Änderung des Logempfängers ist nicht möglich (aber durch die Integration auch nicht unbedingt notwendig).
Die Empfehlung ist, die Entwicklung von Graylog genau zu beobachten, ob nicht doch irgendwann die Lizenz-Daumenschrauben angezogen werden.
Linux-Logging mit rsyslog und syslog-ng
Mit Hilfe dieser beiden Dienste kann man innerhalb von Minuten einen Logging-Service aufsetzen, der getrennt nach Ports (z.B. 5001 für Firewalls, 5002 für Server, 5003 für PCs) Logs empfängt und in eine Datei schreibt.
Aber: es ist und bleibt eine Volltextsuche. Keine Key-Value-Paare, keine Arithmetik, kein IP-Adressverständnis. Sicher, mit grep, sed, awk und sonstigem foo können Auswertungen gefahren werden. Mächtig: ja, intuitiv: nein, grafisch: nein.
Nagios und CheckMK
Beide Systeme sind Monitoring-Systeme und beide haben sich quasi das Thema Logging rangeflanscht. Bei CheckMK kann man solche Regeln definieren: wenn Syslog-Host = Host und wenn Syslog-Text = „*critical*“, dann schalte Host auf rot/critical um. Die Suche innerhalb der Meldungen ist sehr zäh und erinnert mehr an ein etwas verbessertes Webinterface für Linux-Syslog-Suchen. Es wird unserer Meinung nach nie so gut performen wie ein verteilter Cluster wie OpenSearch oder Splunk.
Die Empfehlung ist daher eher auf kleine Umgebungen mit einem ausgewählten Logmanagement.
Splunk
Unter dem Begriff Splunk wird vieles, was oben bereits beschrieben wurde, subsummiert. Splunk ist ein Log-Ausleiter (Heavy Forwarder, Universial Forwarder), ein Logempfänger und Lognachrichten-Zerleger (alles schön über die Web GUI konfigurierbar), eine Oberfläche für Suchanfragen und zur Darstellung von Dashboards sowie ein Konfigurator von Alarmmeldungen.
Zudem lassen sich über Addons viele Dashboards, Zerleger und vordefinierten Suchanfragen für die gängigsten Systeme und Hersteller per Klick installieren.
Splunk kann wie Elasticsearch/OpenSearch verteilt und geclustert werden, womit auch eine gute Skalierung erreicht wird.
Splunk ist eigentlichtm das System, was sich ein Log-Verantwortlicher wünscht, allerdings muss dies teuer bezahlt werden. Pro GB im Jahr muss man etwa 150-200€ rechnen. Bei 100GB pro Tag wären das also ca. 20.000€/Jahr. Schafft man es, weitere Bereiche im Unternehmen in Splunk zu integrieren (z.B. das Marketing oder vergleichbare analytische Abteilungen), macht sich das ggf. bezahlt. Für die durchschnittliche IT-Abteilung wird Splunk eine Nummer zu groß sein.
Die Firma Splunk wurde inzwischen von der Firma Cisco gekauft. Diese integrieren Splunk nun nach und nach in ihre Systeme.
SPL vs. DQL/DSL
Wenn sich bei den erwachsenen Loglösungen alles auf Splunk (SPL) und OpenSearch (DQL) /Elasticsearch (DSL) runterbricht, stellt sich am Ende die Frage der Vergleichbarkeit der Suchabfragen.
Wer seine ersten intensiven Erfahrungen mit der SPL, einer Mischung aus Command Line und SQL-Abfrage, gemacht hat, wird leider enttäuscht auf den Funktionsumfang der DQL/DSL reagieren.
Der größte Unterschied ist, dass die SPL zur Laufzeit der Suchabfragen Variablen erzeugen und verändern kann. So können beispielsweise die Geo-IP-Informationen zur Laufzeit der Abfrage hinzugefügt werden, indem die Kommandos ähnlich wie bei Linux aneinander gepiped werden können. Bei DQL/DSL kann ich nur nach dem suchen, was auch tatsächlich als Dokumente zur Verfügung stehen.
Für einen Kunden nutze ich gerne das Feature, dass die Felder protocol (tcp/udp) und dest_port für die Darstellung zusammengebunden werden zu udp/53 oder tcp/443. Für OpenSearch/Elasticsearch würde das bedeuten, dass logstash die Felder protocol, dest_port und proto_port injesten muss, damit für die Darstellung nur noch proto_port angezeigt werden kann. Dadurch ergeben sich redundante Daten.
Für die DQL/DSL muss man also bereits von Anfang an wissen, was man suchen und darstellen möchte. Viele Dinge lassen sich auch nicht so einfach umwandeln oder nur durch entsprechende Visualisierungen. Die SPL bietet viel mehr Transformationsmöglichkeiten (mit den anschließenden Möglichkeiten: visualisiere mir das hübsch, und nun pack es mir in ein Dashboard), allerdings mit dem entsprechenden Preis.
Fazit
Bei den ausgewachsenen Log-Lösungen ist man gut beraten, wenn man zu OpenSearch greift. Elasticsearch ist ggf. hinsichtlich der Lizenz schwierig oder unsicher, bei Graylog wird es wahrscheinlich vermehrt in die Monetarisierung des Produkts gehen. Splunk ist der Wunschtraum, allerdings gegen den Einwurf großer Münzen.
OpenSearch funktioniert in Docker-Container sehr gut, lässt sich aber auch einfach auf VMs installieren. Kleinere Umgebungen funktionieren schon mit dem ganzen Stack in einem Betriebssystem (single node installation).
